
An end to decades of storage complexity
When it’s possible to store all of your data in a single tier of storage that’s fast enough for all of your demanding applications, large enough to manage all of your data, and affordable enough such that the economic arguments for HDDs no longer apply, everything is simple. When exabytes of data are available in real time, new insights become possible.
Building on their experience of ushering in the age of flash for primary, high-performance applications –VAST Data’s founders sought to address the challenges found across the capacity tier of storage, to unleash access to vast data sets and bring an end to the hard disk era. With new concepts that make it possible to break decades of long-standing storage compromises, the VAST team has reinvented the storage experience and made it possible to now build data centers entirely from flash. These new concepts are only possible beginning in 2018, as a new collection of technologies enable an entirely new storage architecture.
Starting from a new foundation
The VAST Data engineering team had the opportunity to rethink how storage could be built by inventing on a collection of technologies that weren’t commercially available until 2018. More than a retrofit to classic storage architectures, these technologies are used in different and counter-intuitive ways to result in something altogether different.
VAST Data innovation
Legacy storage systems were not designed to work with large, multi-GB flash erase blocks and low-endurance drives. While QLC devices cost significantly less than traditional enterprise flash, it takes a new architecture concept to be able to use these devices and ensure over a decade of device longevity.
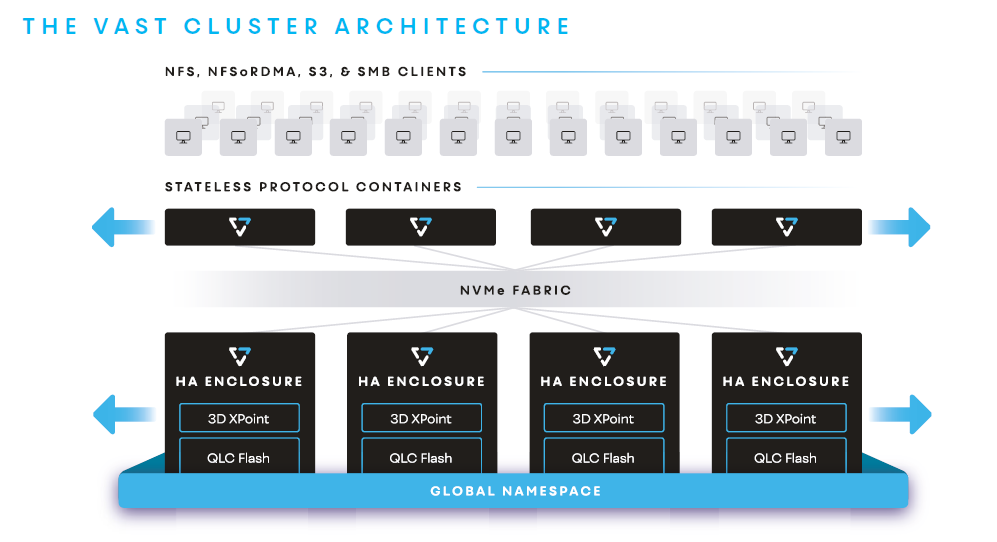
INDIRECT-ON-WRITE FILE SYSTEM
The DASE cluster architecture leverages TBs to PBs of Storage Class Memory (3D XPoint) to buffer writes into global and persistent fabric-attached memory. VAST’s log-based file system creates a layer of indirection for new writes and appends. This indirection enables the system to only write in full, multi-GB QLC flash erase blocks – vastly reducing garbage collection, and enabling an unnaturally higher level of device endurance.
GLOBAL WEAR LEVELING AND WRITE AMORTIZATION
QLC flash wear leveling is done at the global level, and the system balances the needs of transactional workloads with the needs of archive data to deliver an averaged endurance that is greater than what QLC devices provide themselves.
PREDICTIVE DATA PLACEMENT
Moreover, VAST exploits additional context provided by the applications to predictively place data in QLC erase blocks that have a common life expectancy. By eliminating write amplification, VAST systems can be deployed for over a decade… all backed by by VAST Data’s 10-Year Endurance Warrantee.
VAST has broken the cost vs. reliability tradeoff in data protection by developing a new, global approach that provides unprecedented efficiency and resilience.
SHARED-EVERYTHING ERASURE-ENCODED WRITES
Shared-nothing storage nodes have CPUs responsible for a limited number of storage devices in a shared-nothing cluster. The VAST DASE architecture, on the other hand, enables any CPU to directly write to 10s to 1,000s of drives
simultaneously, making it possible for the system to create very wide write stripes without imposing any cluster cross—talk or erasure code coordination.
A MASSIVE, PERSISTENT WRITE BUFFER TO ENSURE WRITE PERFORMANCE
Before VAST, the only way to achieve the right balance of performance and write stripe efficiency would be to use large amounts of DRAM, which is both costly and complicates system architectures because of cache power management and coherency issues. The VAST architecture employs 3D XPoint in a fabric-attached, persistent write buffer to enable fast cluster write speeds while also giving the cluster the time to craft large, QLC-optimized write stripes without the need for expensive DRAM and without the need for cache-coherence or batteries.
A NEW ERASURE CODE TO BREAK THE COST/RESILIENCE TRADEOFF
At the core of nearly every scale-out storage system in the market today is an adaptation of a Reed-Solomon error correction. The basic data reconstruction principle of Reed-Solomon is simple: when a drive within a write stripe is lost, all of the other drives in the system must be read from in order to perform a recovery. When stripes grow very large, Reed Solomon makes large striping impossible because the added time to perform a device rebuild by reading very wide stripes results in an unacceptably high Mean Time to Data Loss (MTTDL).
VAST’s new Global Erasure Codes enable each data protection slice in a write stripe to act as a force-multiplier for cluster rebuild speed. VAST’s declustered error correction can recover a failed device in a fraction of the time that it takes Reed-Solomon, As clusters grow, stripes are distributed across enclosures – the overhead of the system
goes down to 3% while the system becomes more resilient. VAST’s erasure codes are also fail-in-place, to enable instant recovery.
VAST has broken the tradeoff between data reduction efficiency and performance with its Similarity-Based Data Reduction technology. This breakthrough approach combines the global nature of deduplication with the fine-grained byte-granularity of pattern matching to achieve unprecedented levels of storage efficiency without compromising performance or endurance.
Data is first persisted to 3D XPoint so that write speeds are fast, while the system also has time to do aggressive data reduction in the background, all without wearing down flash.
Data is then chunked and fingerprinted with a variablelength hashing algorithm. Unlike conventional deduplication systems, VAST’s hash is not intended to find exact block matches, rather it’s engineered to create a signature of the data used determine the relative distance between other data that is already in the system.
The system then measures the ‘distance’ of new data with other data in the system to find relative similarity, the data is compressed against a cluster of similar blocks, providing the opportunity to find and compress patterns across files with byte-range granularity (1000s of times less sensitive to noise in data than classic deduplication methods).
Data in a similarity cluster is locally decodable, such that the system can simply retrieve the reference block and the deltas to perform a decompressed read within less than a millisecond. You don’t need to decompress petabytes to perform a 4K read, as would be needed with legacy approaches to compressing multiple files.




